Tool: PostgresSQL
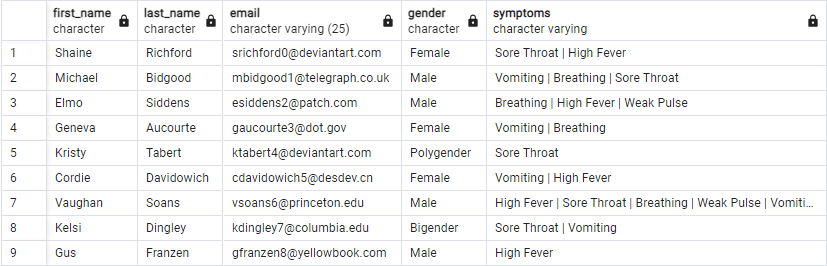
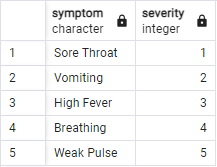
Info Patient data contains a list of symptoms which are manually input into a system. Ordering is unspecific, and data separates symptoms using | delimiter. Symptoms data contains the symptoms and their severity (1-5).
Problem: We want to identify patients by severity. To do this there needs to be a new column for Patients which identifies the most severe symptom from their list of symptoms, and assigns the paired number from Symptoms to that the patient.
Tables:
Setup
DROP TABLE IF EXISTS patients;
CREATE TABLE IF NOT EXISTS patient_info (
first_name CHAR(10) NOT NULL,
last_name CHAR(10) NOT NULL,
email VARCHAR(25) NOT NULL,
gender CHAR(10) NOT NULL,
symptoms VARCHAR NOT NULL
);
INSERT INTO patients VALUES
('Shaine','Richford','srichford0@deviantart.com','Female','Sore Throat | High Fever'),
('Michael','Bidgood','mbidgood1@telegraph.co.uk','Male','Vomiting | Breathing | Sore Throat'),
('Elmo','Siddens','esiddens2@patch.com','Male','Breathing | High Fever | Weak Pulse'),
('Geneva','Aucourte','gaucourte3@dot.gov','Female','Vomiting | Breathing'),
('Kristy','Tabert','ktabert4@deviantart.com','Polygender','Sore Throat'),
('Cordie','Davidowich','cdavidowich5@desdev.cn','Female','Vomiting | High Fever'),
('Vaughan','Soans','vsoans6@princeton.edu','Male','High Fever | Sore Throat | Breathing | Weak Pulse | Vomiting'),
('Kelsi','Dingley','kdingley7@columbia.edu','Bigender','Sore Throat | Vomiting'),
('Gus','Franzen','gfranzen8@yellowbook.com','Male','High Fever');
SELECT * FROM patients;
DROP TABLE IF EXISTS symptoms;
CREATE TABLE IF NOT EXISTS symptoms (
symptom CHAR(11) NOT NULL,
severity SMALLINT NOT NULL
);
INSERT INTO symptoms VALUES
('Sore Throat',1),
('Vomiting',2),
('High Fever',3),
('Breathing',4),
('Weak Pulse',5);
SELECT * FROM symptoms;
Brainstorming
- In order to pair a severity value to the symptom I need all the patient symptoms split.
- I want a unique identifier tied to each patient to ensure I can always join back data to the appropriate patient.
- Splitting symptoms will duplicate all the other columns for each patient. Dropping or grouping will be needed for cleanup.
- After splitting symptoms, I can join together the two tables on symptoms to get severity per symptom.
- Following the join I want a table that contains only the highest severity per patient.
- Join this new table to the original patient table to get a final table that contains all the patients and their symptoms with the highest severity.
Testing (using views)
Even though I want to split my data, I need to make sure to setup the patient table with a unique identifier since this data does not contain unique IDs.
ALTER TABLE patients ADD COLUMN id SERIAL PRIMARY KEY;
SELECT id, symptoms FROM patients;
Next will be splitting the patient symptoms to get each symptom for the each patient.
DROP VIEW IF EXISTS split_symptoms;
CREATE TEMP VIEW split_symptoms AS
SELECT
id, -- don't need extra patient info
symptoms, -- to view original value
unnest(string_to_array(symptoms, ' | ')) AS symptoms_split
FROM patients;
SELECT * FROM split_symptoms;
Now I want to join the data together to get severity per symptom tied to each patient.
DROP VIEW IF EXISTS merged_patient_symptoms;
CREATE TEMP VIEW merged_patient_symptoms AS
SELECT *
FROM split_symptoms as ss
LEFT JOIN symptoms AS smt
ON (ss.symptoms_split = smt.symptom)
ORDER BY id ASC;
SELECT * FROM merged_patient_symptoms;
To get the highest value for severity from this merged table, I want to use MAX() function on the severity. However, to use MAX() aggregation I need to pair this with groupby. Since the goal is to pair highest severity to patients, I can drop all other columns that aren’t needed.
DROP VIEW IF EXISTS id_maxseverity;
CREATE TEMP VIEW id_maxseverity AS
SELECT
id,
max(severity) AS severity_rank
FROM merged_patient_symptoms
GROUP BY id;
SELECT * FROM id_maxseverity;
Last step would be to join together the two tables to get severity per patient.
DROP VIEW IF EXISTS final_patient_table;
CREATE TEMP VIEW final_patient_table AS
SELECT
pt.id
pt.first_name,
pt.last_name,
pt.email,
pt.gender,
pt.symptoms,
ms.severity_rank AS severity
FROM id_maxseverity AS ms
INNER JOIN patients AS pt
ON (pt.id = ms.id);
ORDER BY id ASC;
SELECT * FROM final_patient_table;
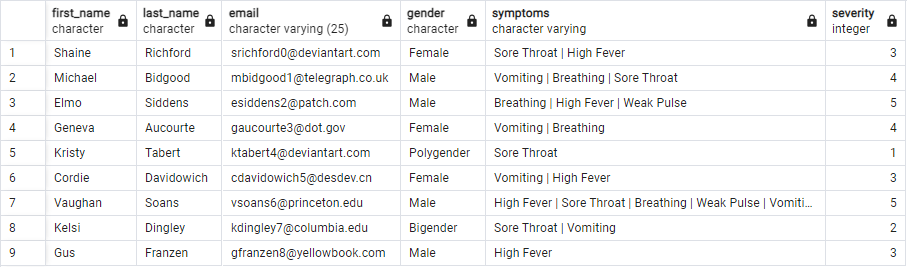
Final Query
The temporary views are good for testing purposes, but not good for producing a real solution. This is what my final query looks like now that I know the steps I need to take to produce what I need.
ALTER TABLE patients ADD COLUMN id SERIAL PRIMARY KEY;
SELECT id, condition FROM patients;
DROP TABLE IF EXISTS patients_final;
WITH merged_patient_symptoms (id, symptoms, symptom_split, symptom, severity)
AS (
SELECT *
FROM (
SELECT
id,
symptoms,
unnest(string_to_array(symptoms, ' | ')) AS symptom_split
FROM patients
) as ss -- split symptoms table
LEFT JOIN symptoms AS smt
ON (ss.symptom_split = smt.symptom)
) -- CTE for merged table
SELECT
pt.id
pt.first_name,
pt.last_name,
pt.email,
pt.gender,
pt.symptoms,
ms.severity_rank AS severity
INTO patients_final
FROM (
SELECT
id,
max(severity) AS severity_rank
FROM merged_patient_symptoms
GROUP BY id
) AS ms -- max severity table
INNER JOIN patients AS pt
ON (pt.id = ms.id)
ORDER BY id ASC;
SELECT * FROM patients_final;
Last modified on 2024-07-12
Comments Disabled.